TL;DR
- 카카오 카프카 클러스터는 초당 1,800만 건 메시지를 처리한다.
- 주키퍼는 홀수 구성하는 게 좋고 5대 구성하는 것이 좋다.
- Non-Raid 를 사용해 디스크 독립 구성을 한다.
- 기본적으로 토픽 리텐션은 3일(주말 대비), 토픽 별로 따로 관리하는 경우도 있다.
- 소량의 메시지 소실을 감안하고 빠른 장애 복구를 최우선으로 클러스터를 구성한다.
- 메트릭 정보는 프로메테우스에 저장해 그라파나로 시각화한다.
- 로그는 파일피트로 수집 후 나이파이로 재처리 후 엘라스틱서치로 저장 후 키바나로 시각화한다.
- Kraft Mode 도입을 아직, 4.x부터 도입 예정.


- 2018년 처음 클러스터 소개
- 데이터 흐름을 모아주는 실시간 분산 스트리밍 플랫폼

- 전체 1.5조 메시지
- 초당 1,800만 건 메시지 처리
- 하루 2.1PB 들어오고 3.8PB가 나감

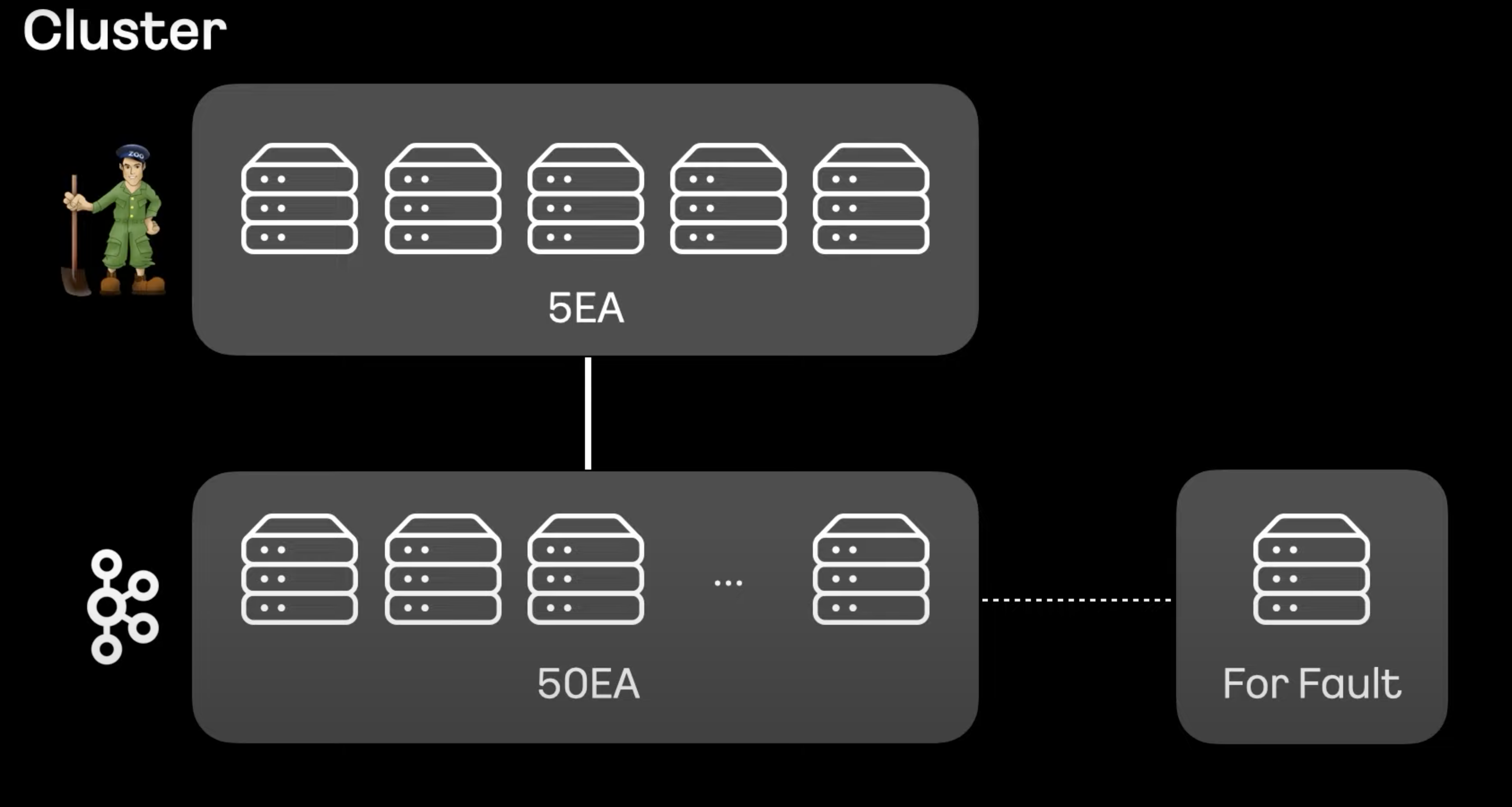
- 주키퍼는 과반수 투표로 카프카를 코디네이션하기 떄문에 홀수 구성이 필요하다.
- 2대까지 장애 보장하는 5대로 구성, 주키퍼 공식 사이트에 3대 5대는 차이가 크지만 그 이상은 크게 차이가 없다.
- 카프카는 50대까지 묶어서 구성, 너무 적으면 높은 퍼포먼스에 대한 처리가 힘들고, 너무 많아지면 서로 간 부하와 장애 영향이 커져 수년 간 모니터링 끝에 해당 구성을 표준으로 구성했다.
- For Fault라는 장비를 추가 마련해 장애 처리

- 2018년보다 많은 부분이 바뀌었다.
- 특히 디스크와 메모리 부분이 크게 바뀌었다.

- 컨플루언트는 Raid 1+0 를 권장한다. 트래픽이 크지 않을 때는 괜찮다. 하지만 트래픽이 많으면 병목현상과 디스크 한 대가 장애난 뒤 리빌딩이 완료될 때까지 전체 디스크가 흔들리는 이슈가 있었다
- 독립 구성하고 카프카 내부적으로 리플리카 위에 복제하는 게 더 효율적이라고 판단.
- 일반적으로는 권고사항이 좋지만 모든 케이스에 정답이 아닐 수 있다.
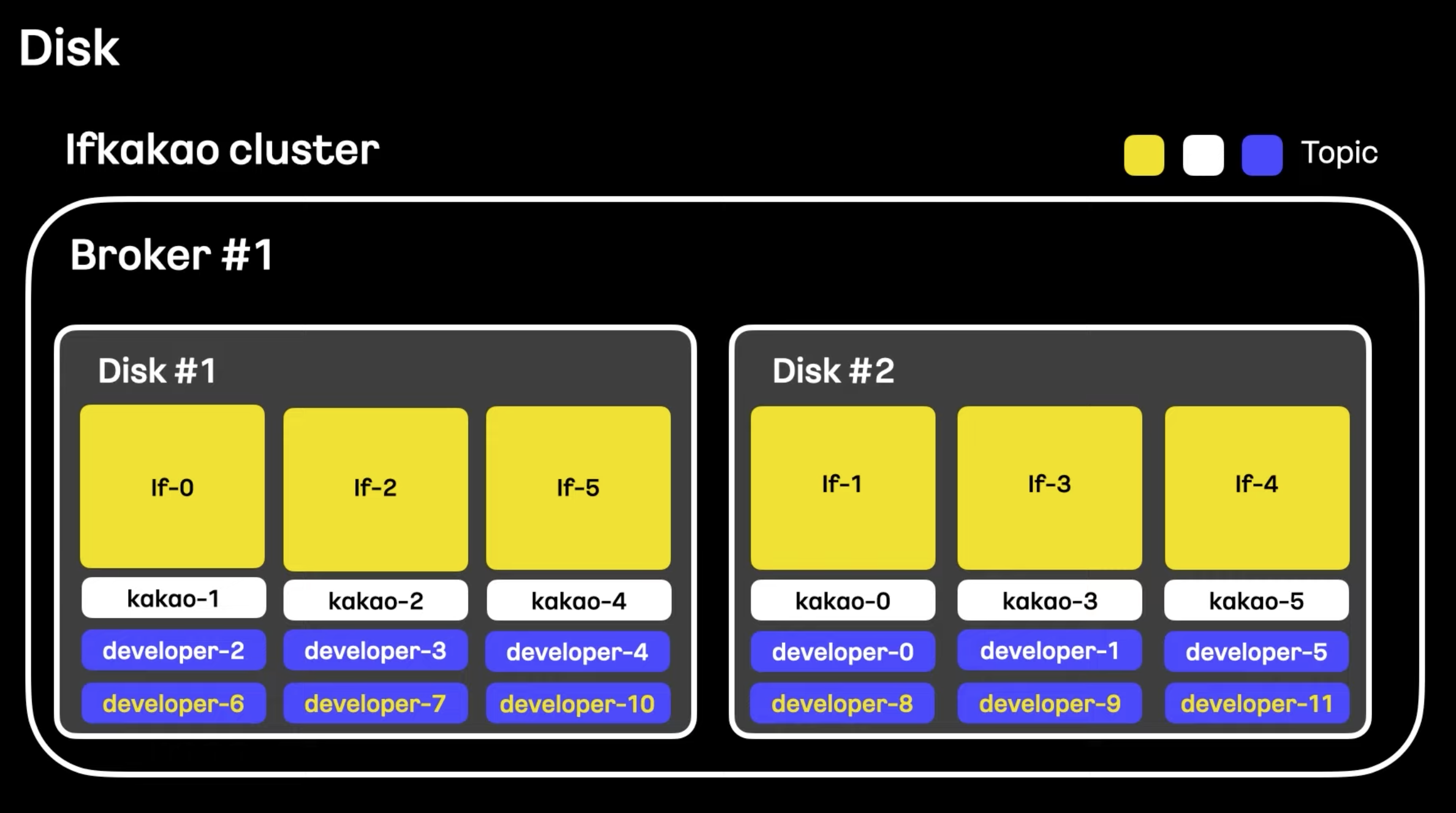

- 하나의 브로커에 디스크를 더 많이 할당하니 토픽을 분산하게 되면서 트래픽이 분배된 것을 볼 수 있다.
- 파티션 분배가 균등하게 이루어지게 되고 여러 개의 디스크에서 좀 더 많거나 버스트한 트래픽을 여유있게 처리할 수 있게 된다.
- 장애 빈도는 높아질 수 있음. 메모리가 더 많이 필요할 수 있음.

- 95% 이상이 디스크 문제였다.
- 디스크 장애를 자동으로 해결해주는 디스크 매니저를 자체 개발했고 디스크 교체 후 정상화 여부를 카톡으로 알려주도록 개발

- SSD 쓰지 않고 Spindle Disk 쓰는 이유.
- 애플리케이션 버퍼를 커지지 않고 커널 단에서 제로카피를 해서 바로 처리하기 때문에 훨씬 빠른 네트워크 전송과 쓰루풋을 가진다.
- 또 직접 flush 하지 않고 OS 백그라운드 처리할 때까지 기다리며 커널에서 Write 함수 위주로 직접 쓰기를 한다. -> flush 파

- 세그먼트 default 1GB 형태로 묶어서 저장하는데, 시퀀셜하게 동작하기 때문에 SSD에 비하여 Read, Write 성능이 밀리지 않고 오히려 높게 나오기도한다.

- 카프카는 제로카피 사용하기 때문에 힙메모리 사용하지 않고 Page Cache 사용하여 디스크 의존도가 낮다.
- 카프카 공홈에서 힙 메모리는 최대 6GB 이하로 설정할 것을 권장한다.
- 카프카 외 다른 애플리케이션을 띄우지 않는 것을 권장한다.

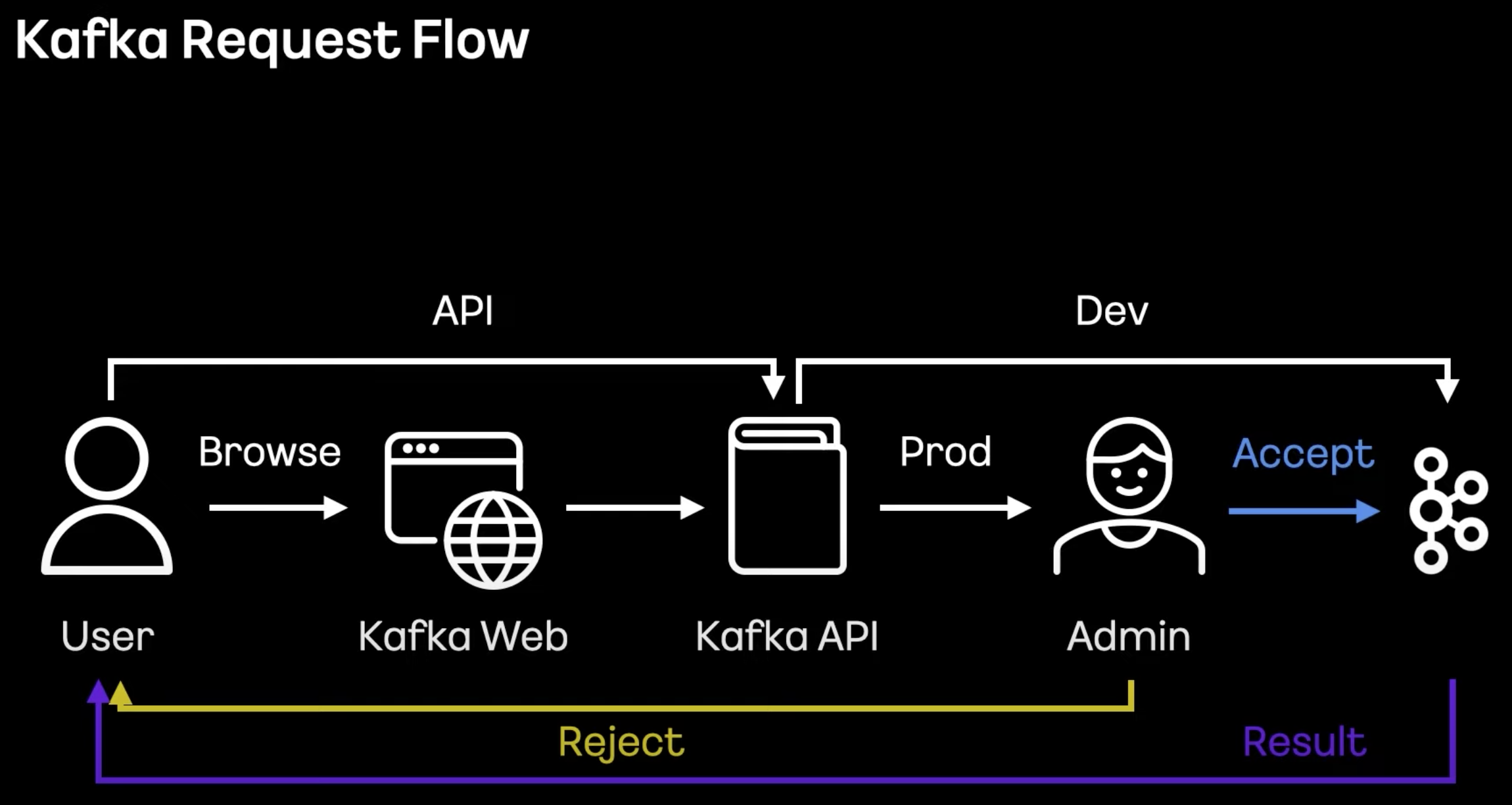
- Kafka 웹을 만들어 토픽 생성 및 파티션변경을 자동화했음
- Stage 는 자유롭고, 실제 서버는 TF 담당자들이 승인 후 사용할 수 있도록 구성




- 전반 보관 주기, 원래는 7일인데 3일로 설정 (주말을 대비하여)
- 이 값이 크면 장애 후 복구에 오래걸림

- 토픽 별로도 관리.
- 피로 대비 긴 유지 기간은 조정할 필요가 있다.

- 정전으로 브로커 다운 되었을 때 가장 최근 메시지 지닌 리더가 사라질 때까지 끝까지 기다린다.
- 짧은 시간 안에 복구되면 상관 없는데 지연될 경우 디스크 장애면 계속 기다리면 계속 기다리게 된다.
- 메시지 소실을 감안하더라도 true로 하여 빠르게 복구한다.

- num.replica.fetchers: 1 -> 4
- num.network.threads: 12 이상
- num.io.threads: 12 이상
- auto.create.topics.enable: produce 시 토픽 없을 경우 자동 생성
- log.dirs

- 버전 올라가면서 버그도 많이 해결됨.


- 메트릭 정보는 프로메테우스에 저장해 그라파나로 시각화
- 로그는 파일피트로 수집 후 나이파이로 재처리 후 엘라스틱서치로 저장 후 키바나로 시각화 에러 시 카톡 발생



- default.replication.factor 을 min.insync.replicas 보다 1개 더 주는 것이 좋다.

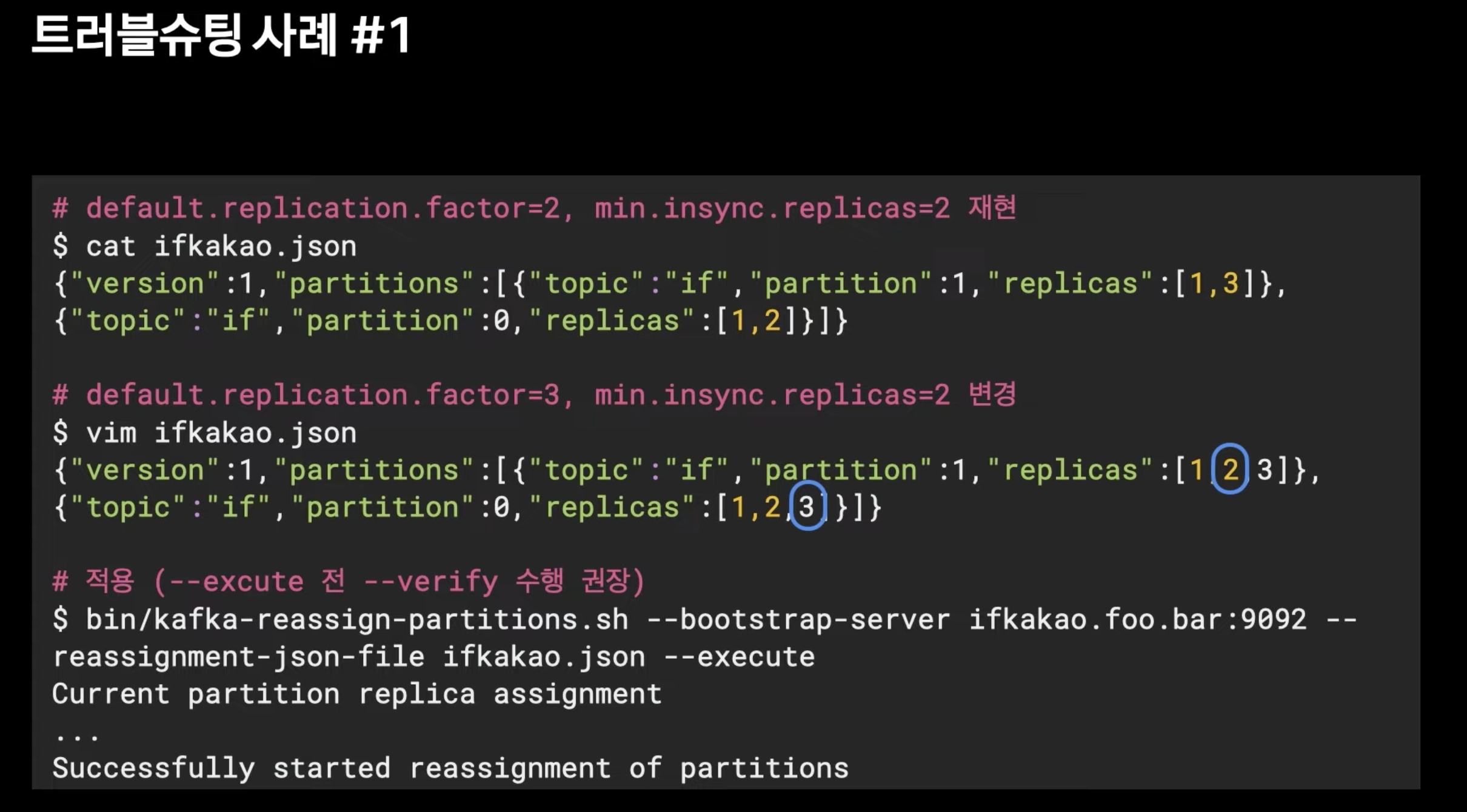
- RF 바꿀 수 있다.



- 특정 로그가 삭제되지 않은 버그가 있었따.
- retenion.bytes 조정하여

- Kraft Mode 를 도입하려고 계획 중이다.
- 아직까지는 운영에 적요되지 않고 있다.
- 4.x부터 도입할 계획이라고한다.
'DataOps > Kafka' 카테고리의 다른 글
| [Kafka] 컨슈머 그룹 - 토픽 컨슘 관계(?) 삭제 (0) | 2024.05.02 |
|---|---|
| Slash2023 - 토스ㅣSLASH 23 - Kafka 이중화로 다양한 장애 상황 완벽 대처하기 (0) | 2023.10.10 |
| [카프카] Rebalancing (0) | 2023.09.06 |
| [Kafka] UI Tools 분석글 공유 (0) | 2023.03.13 |
| [Kafka] 카프카란? (0) | 2023.03.10 |



댓글