개요
- 데이터 읽기와 쓰기 작업 요청 들어왔을 때 엘라스틱서치 내부가 어떤 단계를 거쳐 동작하는지 살펴본다.
- 어떻게 요청의 동시성 제어를 하는지?
- 샤드에 문제가 생겼을 때 어떻게 복구되는지
8.1 엘라스틱서치의 데이터 분산 처리 과정
8.1.1 쓰기 작업 시 엘라스틱서치 동작과 동시성 제어
쓰기 작업의 3단계

1. 조정 단계(coordination stage)
2. 주 샤드 단계(primary stage)
- 요청을 넘겨받은 이후 수행하는 작업들
- in-sync 복제본
- 마스터 노드가 관리하는 작업을 복제받을 샤드 목록
- 주 샤드는 in-sync 복제본에 병렬적으로 요청을 넘긴다.
- 모든 복제본들이 작업을 성공적으로 수행하고 주 샤드에 응답을 돌려주면 주 샤드가 작업 완료 응답을 보낸다.
3. 복제 단계(replica stage)
- 각 in-sync 복제본 샤드는 주 샤드에게 받은 요청을 로컬에서 수행하고 주 샤드에게 작업이 완료됐음을 보고하는 단계
→ 종료는 역순이다.
- 최초 요청 받아 전달했던 노드에게 작업 완료 결과를 보내야 조정 단계가 종료된다.
메세지 순서의 역전
- 분산 환경에서 여러 작업을 병렬적으로 보내면 메세지 순서의 역전이 있어날 수 있다.
- 그 이유를 한번 살펴보자
낙관적 동시성 제어
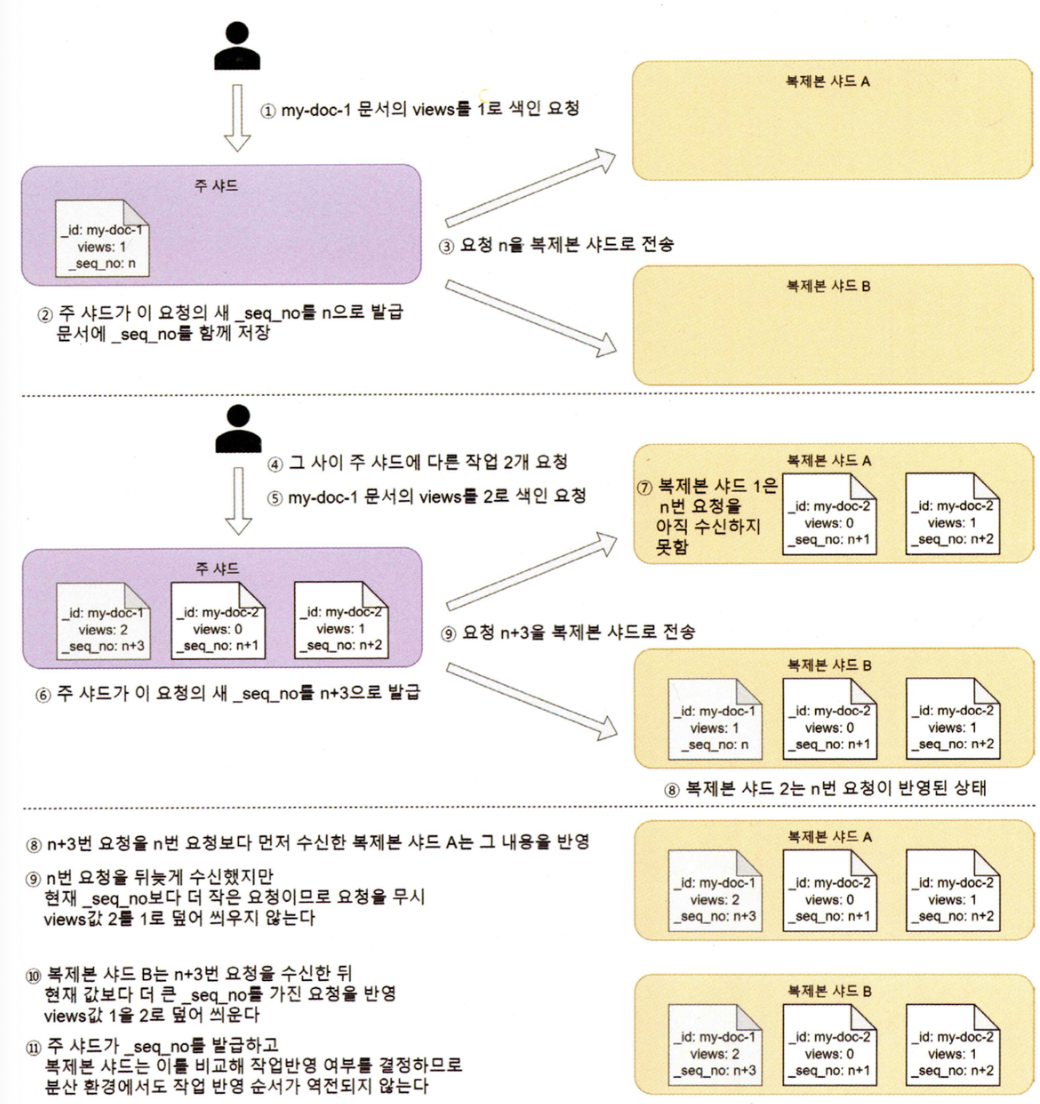
- _seq_no
- 의미
- 각 주 샤드마다 들고 있는 시퀀스 숫자이며, 매 작업마다 1씩 증가한다.
- 문서를 색인할 때 이 값을 함께 저장한다.
- 엘라스틱 서치는 문서 색일할 때 이 값을 함께 저장한다.
- 엘라스틱서치는 이 값을 역전시키는 변경을 허용하지 않음으로 요청 순서의 역전 적용을 방지한다.
- 쓰임새
- 분산 처리에서 _id는 같은데 _seq_no 값이 더 작은 색인 요청을 받으면 작업을 수행하지 않는다.
- 의미
- _primary_term
- 의미
- 주 샤드가 새로 지정될 때 1씩 증가한다.
- 주 샤드를 들고 있는 노드에 문제가 발생했을 때 복제본 샤드 중 하나를 주 샤드로 지정하는데, 이전 주 샤드에서 수행했던 작업과 새로 임명된 주 샤드에서 수행했던 작업을 구분하기 위해 필요한 값
- 쓰임새
- 어떤 주 샤드에서 수행된 작업인지 구분하기 위해 사용된다.
- 의미
- _version
- 의미
- 마찬가지로 동시성을 제어하기 위한 메타데이터
- 이름 그대로 문서의 버전을 표현
- 차이점
- 클라이언트가 직접 지정할 수 있다.
- version_type 을 external or external_gte 로 설정하면 클라이언트가 직접 지정해 색인을 요청할 수 있다.
- version_type internal 은 버전이 자동으로 붙는 타입
- 클라이언트가 직접 지정할 수 있다.
- 타입
- 동작
- 지정하지 않으면 ES 가 자동으로 값을 매긴다.
- 주의
- 더 높은 버전으로만 업데이트가 가능하다.
- 쓰임새
- 다른 스토리에서 저장된 데이터의 버전을 따로 관리하고 있고, 그 데이터를 엘라스틱 서치로 받아와 2차 스토리지로 동기화하여 사용한다든지 하는 경우 활용하기 좋음
- 의미

8.1.2 읽기 작업 시 엘라스틱서치 동작
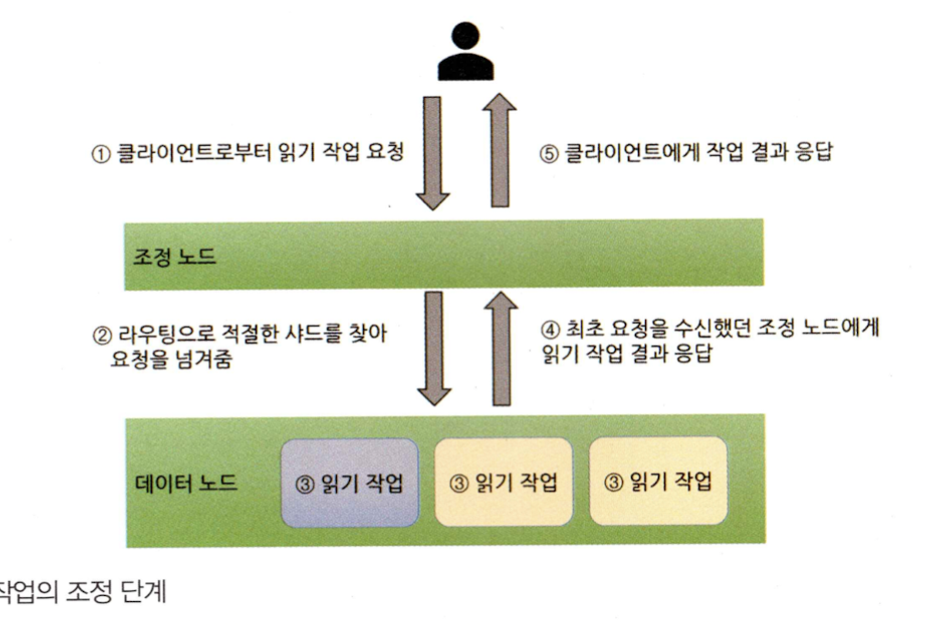
- 쓰기 작업과 다르게 읽기 요청은 복제본 샤드로 넘어갈 수 있다.
- 문서 단건 조회라면 하나의 샤드에 요청이 넘어가겠지만 검색 등 다수의 샤드에 요청을 넘겨줄 수 있다.
- 요청을 넘겨받은 각 샤드는 로컬에서 읽기 작업 수행한 뒤 그 결과를 조정 노드로 돌려준다.
- 샤드에 색인이 완료됐지만 특정 복제본에는 완료되지 않은 상태의 데이터를 읽을 수도 있다
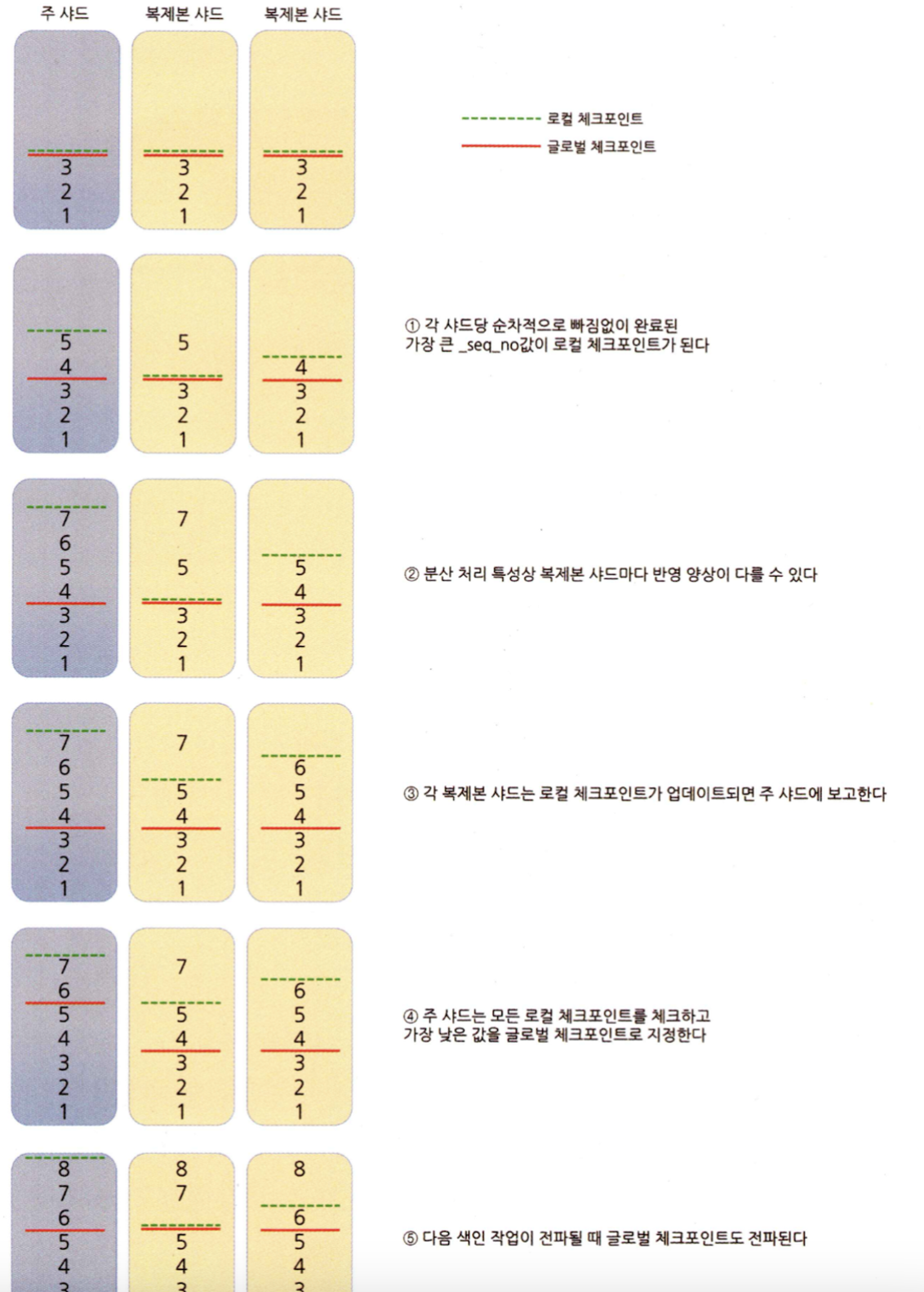
8.1.2 체크포인트와 샤드 복구 과정
샤드 복구
- 노드 재시작되면 샤드 복구 작업이 진행되는데, 이때 주 샤드의 내용과 일치하는지 파악할 필요가 있다.
- p_t 과 s_n 조합해서 샤드와 샤드 사이에 어떤 반영 차이점이 있는지 알 수 있다.
- 글로벌 체크포인트를 비교해서 필요한 작업만 재처리하여 복구한다
- 세그먼트 파일을 통째로 전송하는 것보다 훨씬 효율적이다.
주 샤드의 글로벌 체크포인트와 샤드의 로컬 체크 포인트
- 복제본 샤드가 색인을 완료하면 응답하고 로컬 체크포인트를 1 증가시킨다. 이때 주 샤드는 가장 낮은 로컬 체크포인트를 글로벌 체크포인트로 기록한다.
논리적 삭제와 복구 작업
- 루씬 레벨에서 엘라스틱서치가 수행하는 쓰기 작업 2가지
- 새 문서의 색인
- 기본 문서의 삭제
- 엘라스틱 서치는 논리적 삭제를 도입하여, 최근 삭제한 문서를 일정 기간 보존해 두고 작업 재처리에 활용한다.
- 루씬에 색인된 문서가 재처리에 필요한 정보를 모두 들고 있어서 재처리 가능
샤드 이력 보존(shard history retention leases)
- 재처리할 내용을 추적하는 메커니즘
- 루씬의 세그먼트가 병합되는 도중에도 샤드 이력은 지정한 기간 동안 보존된다.
- 관련 옵션
- index.soft_deletes.retention_lease.period
- default 12시간
- 이 기간을 넘겨서 샤드 이력이 만료된 이후 수행되는 복구 작업에는 작업 재처리를 이용하지 않느다. → 세그먼트 파일을 통째로 복사하는 방법을 사용한다
- index.soft_deletes.retention_lease.period
8.2 엘라스틱서치의 검색 동작 상세
- 읽기 동작 중에서도 검색 동작에 대해 상세히 알아본다.
- 각 레벨에서 매칭되는 문서를 어떻게 판정하고 점수를 계산하는지
- 어떻게 캐시가 동작하는지
8.2.1 엘라스틱서치 검색 동작 흐름
엘라스틱서치 검색 동작 흐름 개괄
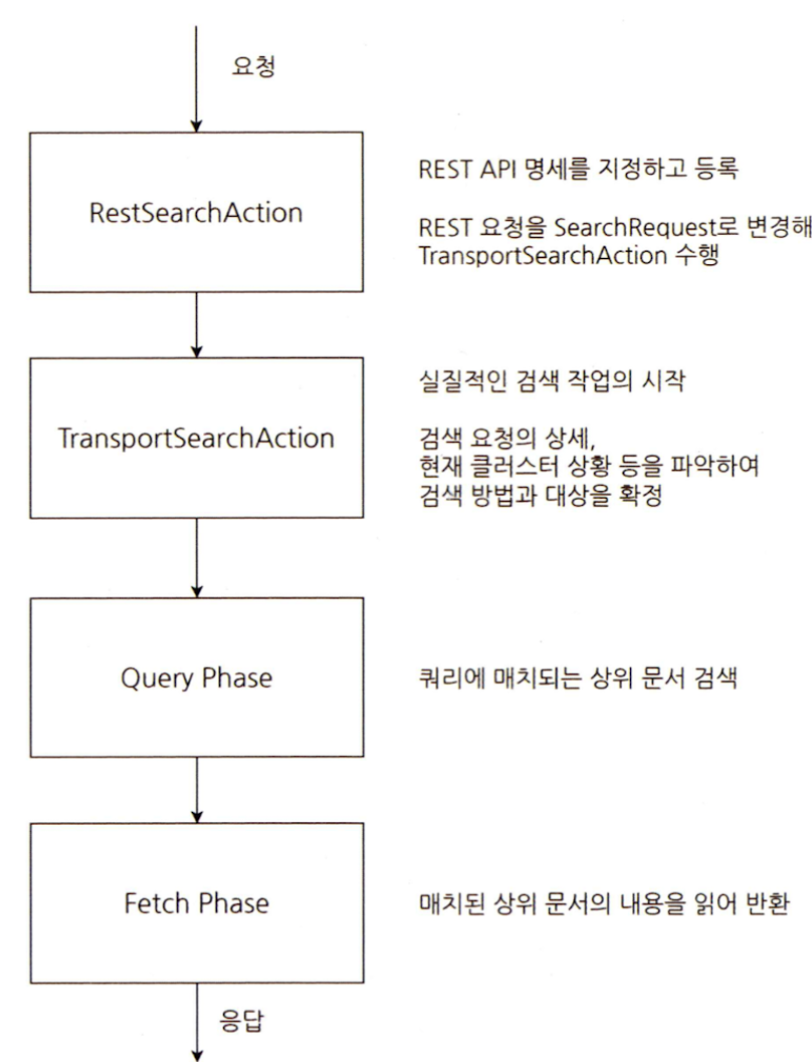
- RestSearchAction 클래스의 prepareRequest 메서드에서 들어온 REST 요청을 확인한다. (주샤드)
- REST 요청을 엘라스틱서치 내부에서 사용할 요청으로 변경해 엘라스틱서치 내부 클라이언트에게 작업 수행을 의뢰한다. (주샤드)
- 이 요청은 이후 TransportSearchAction 인스턴스가 받아서 수행한다. (주샤드 → )
- 검색 요청과 현재 클러스터 상태를 분석해 상황에 맞는 적절한 검색 방법과 대상을 확정하고 본격적인 검색 작업을 뒤쪽 페이즈로 넘긴다. (검색 대상으로부터 실제 인덱스 목록을 확정, 어떤 샤드에 검색 요청을 보낼지를 정한다),
- 그 뒤 과정은 크게 추상화 2가지 페이즈로 나눈다
- query
- 쿼리에 매치되는 상위 문서를 검색하는 작업을 수행한다 (조정 노드가 검색 요청을 분선 전송하는 부분부터 요청에 대한 응답을 받을 때까지)
- 확정한 검색 대상 샤드가 있는 여러 노드로 검색 요청 분산해 전송
- 루씬 레벨의 검색 수행 (데이터 노드)
- 상위 문서의 docId를 수집하며 유사도 점수를 계산
- 각 샤드는 샤드 내에서 판단한 문서의 docId를 조정 노드에 반환
- 조정 노드가 각 샤드 검색 받아 fetch 수행할 문서 확정, 매치된 상위 문서의 내용을 읽어 변환하는 작업을 수행한다.
- fetch
- 해당문서를 들고 있는 샤드가 위치한 노드에 fetch 요청 분산해 전송
- 요청 받은 데이터 노드는 요청 받은 문서의 내용을 읽어 조정 노드에 반환
- 조정 노드는 그 응답을 모아 최종 응답을 생성
- query 페이즈가 끝난 다음 작업부터 여기까지의 작업이 fetch 페이즈의 작업에 속한다.
다른 API도 기본적으로 위 흐름과 비슷하다.
생성 작업
- RestCreateIndexAction 클래스가 REST API 상세 등록
- TransportCreateIndexAction 클래스가 실제 동작을 정의
엘라스틱서치 검색 동작 흐름 상세
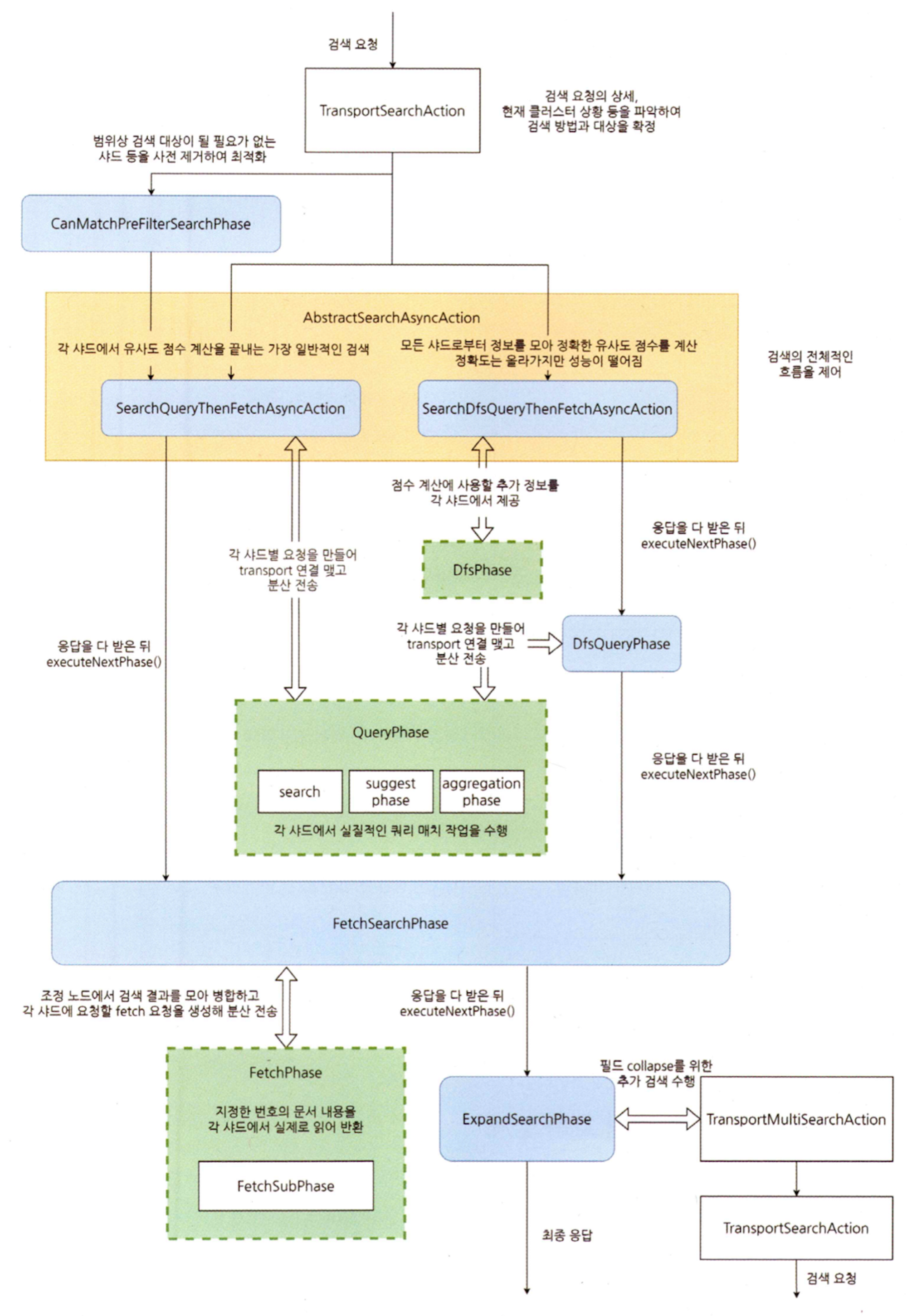
- 검색 동작 흐름을 상세하게
TranspotSearchAction
- preference 있을 때 검색 대상
- 어떤 노드와 샤드를 우선해서 검색할 것인지 지정하는 매개변수
- 원하는 샤드가 있는지 체크하고 없다면 다른 노드의 샤드를 대상으로 지정 → 이름 그대로 선호 옵션
- 종류
- _only_local: 로컬에 들고 있는 샤드만을 대상으로 검색 수행
- _local: 가능하면 로컬에 들고 있는 샤드를 우선으로 검색 수행, 불가능하며 다른 노드의 샤드를 대상으로 지정
- _only_nodes:<node-id>,<node-id>
- 지정한 노드 ID가 들고 있는 샤드를 대상으로만 검색을 수행한다.
- 검색 대상이 될 샤드를 들고 있어야 한다.
- _prefer_nodes:<node-id>,<node-id>
- 지정한 노드 ID가 들고 있는 샤드를 우선해서 검색한다
- _shards:<shard>,<shard>: 샤드 번호를 직접 지정해 해당 샤드 대상으로만 검색을 수행한다.
- 그 외 문자열
- 원하는 문자열 자유롭게 지정하 수 있다고한다 → 문자열 해시 값으로 노드 우선순위 지정 → 같은 노드가 요청을 받도록해서 캐시를 최대한 활용하고자 할 때 사용
- 물론 클러스터 상태 변햇다면 달라진다.
- preference 없을 때 검색 대상
- 적절한 노드 선정
- adaptive replica selection
- 그간 통게 데이터, 검색 스레드 풀 상황 고려해 응답을 빨리 돌려줄 것으로 예상되는 노드를 선정하는 방법
- 조정 노드에서 보낸 이전 요청에 대한 응답 속도나, 이전 검색 요청에 시간이 얼마나 소요됐는지 등
- 관련 옵션
- cluster.routing.use_adaptive_replica_selection 클러스터 설정을 false 로 지정해 끌 수 있다.
- false 로 지정하면 랜덤으로 노드 선정
- cluster.routing.use_adaptive_replica_selection 클러스터 설정을 false 로 지정해 끌 수 있다.
- adaptive replica selection
- 적절한 노드 선정
CanMatchPreFilterSearchPhase
- 검색 대상의 샤드 수가 128개를 초과하거나, 검색 대상이 읽기 전용 인덱스를 포함하거나, 첫 번째 정렬 기준에 색인된 필드가 지정된 경우 수행된다.
- 이 사전 작업의 비용은 낮은 편이다.
- 의미
- 확실히 검색 대상이 될 필요가 없는 샤드를 사전 제거한다
- 최적화 과정
- 인덱스의 메타데이터를 이용해 타임스탬프 필드 범위상 매치되는 문서가 없는지 체크
- 갹 샤드의 최솟값과 최댓값을 가지고 샤드를 정렬해 상위에 올라올 문서를 보유한 샤드가 먼저 수행되도록 최적화하는 등 다양한 방법이 사용된다.
AbstractSearchAsyncAction
- search_type의 기본값은 query_then_fetch
- query_then_fetch
- 각 샤드에서 검색 쿼리 수행하고 매치된 상위 문서 수집할 때도 유사도 점수 계산을 끝내는 가장 일반적인 형태의 검색
- dfs_query_then_fetch (Distributed frequency search)
- 모든 샤드로부터 사전에 추가 정보를 모아 정확한 유사도 점수를 계산
- 이 경우 정확도는 올라가지만 성능이 떨어진다.
- AbstractSearchAsyncAction 확장하여 DFS 전용 클래스 사용
- query_then_fetch
SearchPhase
- 검색 동작은 다음 페이즈로 전환되는 부분을 중점으로 보면 흐름을 읽기가 편한다.
SearchDfsQueryThenFetchAsyncAction
DfsQueryPhase
- 각 샤드에서 보낸 PfsPhase 작업 결과로부터 검색 요청 만들어 다시 각 노드로 분산 전송
- SearchService executeQueryPhase 메서드 거쳐 QueryPhase 에서 본격적인 쿼리 매치 작업 수행
- FetchSearchPhase 넘어간다.
SearchQueryThenFetchAsyncAction
QueryPhase

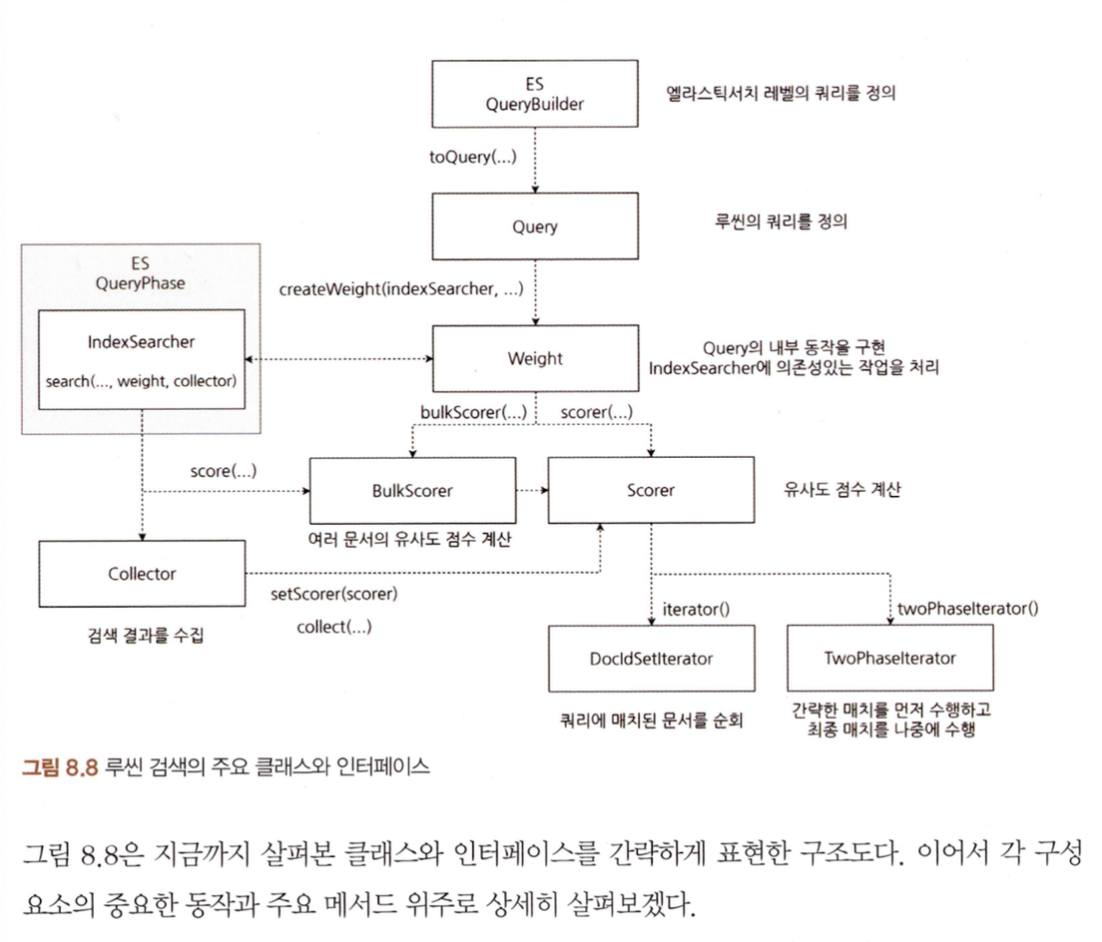
IndexSearcher
- 루씬 인덱스내의 문서를 검색할 때 사용하는 클래스
- search(query, collector):
- 엘라스틱서치는 QueryPhase에서 IndexSearcher의 search(query, collector) 메서드를 호출해 검색을 수행한다.
QueryBuilder
- 엘라스틱서치 레벨의 쿼리를 정의하는 인터페이스
- 쿼리 이름은 무엇인지, 이 쿼리의 DSL 은 어떻게 파싱하고 어떻게 직렬화할지 등을 정의한다.
- toQuery: 엘라스틱서치 쿼리로 루씬의 Query를 생성한다.
Query
- 루씬 쿼리를 정의한느 추상 클래스
- createWeight
- Weight 생성
- rewrite
Weight
- Query 내부 동작을 구현하는 추상 클래스
- score
- Scorer를 생성한다
- bulkScorer
- BulkScorer 생성
- IndexSearch의 search 메서드 내부에서 호출된다.
- explain
- 쿼리 수행의 중간 진행 과정과 유사도 점수 계산 과정을 자세히 설명한다.
Scorer
- iterator
- 매치된 문서의 순회를 담당하는 DocIdSetIterator 를 반환한다.
- twoPhaseIterator
- 무거운 매치 작업을 두 개 페이지로 나누어 진행하도록 하는 TwoPhaseIterator 반환
- score:
- 현재 문서의 유사도를 점수로 계산하여 반환
- float,
- docId
- 현재 문서의 doc ID 반환
- docId 2개
- 로컬 docId
- 세그먼트마다 기준 docId 오프셋이 있음
- 글로벌 docId
- 로컬 doc ID 합산
- 로컬 docId
BulkScorer
- 여러 문서를 대상으로 한 번에 유사도 점수를 계산하는 추상 클래스
DocIdSetIterator (DISI)
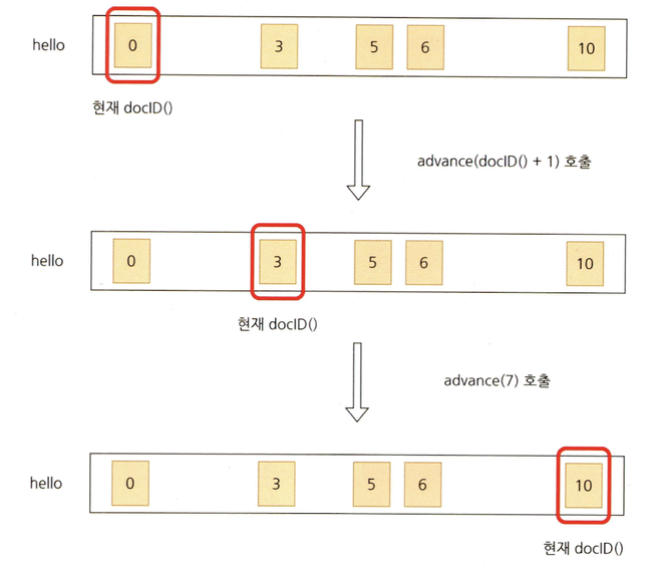
- 매치된 문서의 순회를 담당하는 추상 클래스
- cost
- 순회에 필요한 비용의 추정값 반환
- 적당한 근사값 혹은 하드코딩된 상수를 반환
- docID:
- 현재 문서의 doc ID를 반환한다
- advance(target)
- doc ID target 값 이상인 첫 번째 매치되는 문서로 DocIdSetIterator 순회를 전진시킨다.
- nextDoc
- 매치된 다음 문서로 DocIdSetIterator 전진시킨다.
- ㅇ
Collector, LeafCollector
- 검색 결과를 수집하는 동작을 정의하는 인터페이스
- 유사도 점수나 정렬 기준 등을 계산하거나 확인하며 상위 결과를 수집하는 동작 등을 수행한다.
conjunction(결합, 연결) 검색과 DocIdSetIterator 순회
- conjunction 검색
- AND 성격의 검색으로 주어진 쿼리의 매치 조건을 모두 만족해야 최종 매치된 것으로 판단한다.
- disjunction 검색
- OR 성격 검색으로주어진 쿼리 중 하나만 만족해도 매치된 것으로 판단한다.
8.2.3 캐시 동작
- 검색 성능이 아쉽다면 캐시를 잘 활용하고 있는지 검토해야한다.
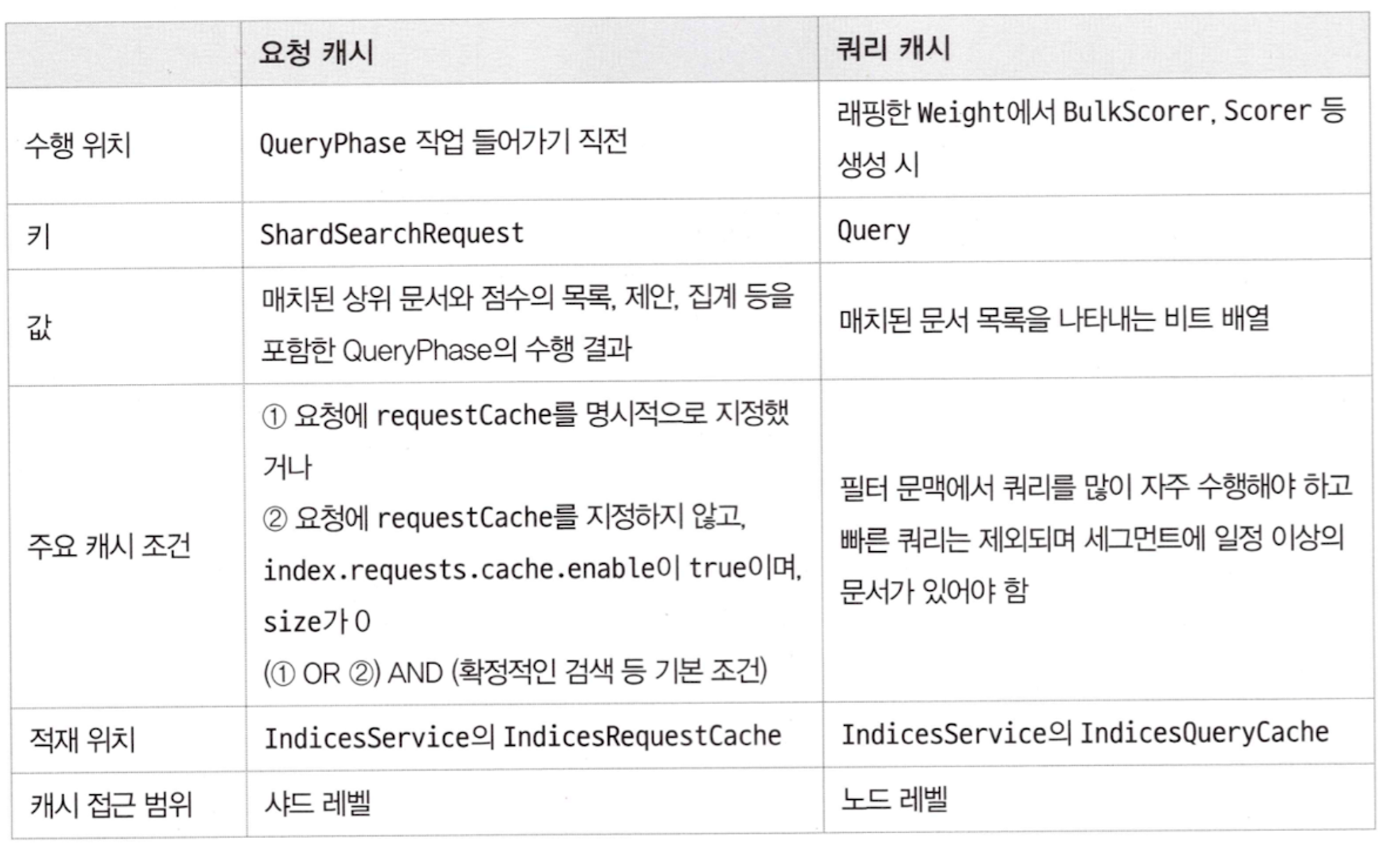
샤드 레벨 요청 캐시
- The request cache is a cache that stores a task performed in the query phase at a shard level when performing a search.
수행 위치
- QueryPhase 작업에 들어갈 때 동작한다.
- QueryPhase execute 가 수행되기 전 SearchService 의 executeSearch 메서드에서 캐시 작업이 수행된다.
- ShardSearchRequest와 대상 인덱스 설정을 보고 캐시 가능한 요청인지 여부를 파악한다
조건
- search_type이 query_then_fetch
- scroll 검색이 아니어야 한다
- profile 요청이 아니어야 한다.
- now 들어간 시간, 표현이나 random 같이확정되지 않은 형태의 조건이 들어간 검색도 캐싱 대상에서 빠진다.
- 검색 API 호출할 때 requestCache 매개변수를 명시적으로 true 혹은 false 확인
- 매개변수 명시적으로 지정하지 않는다면 index.requests.cache.enable 인덱스 설정 확인
- default 는 true
키
- 요청이 캐시 대상이라는 사실을 확인하면 캐시 키를 만든다.
- 2단계
- ShardSearchRequest 주요 내용을 바이트로 직렬화
- 인덱스, 샤드 번호와 검색 요청 본문 내용 포함
- 즉 같은 검색 요청이어야 캐시 적중
- SearchPlugin 인터페이스의 getRequestCacheKeyIdfferentiator 메서드를 오버라이드한 플러그인에서 지정한 캐시 키 변경 로직을 적용
- ShardSearchRequest 주요 내용을 바이트로 직렬화
대상 값
QueryPhase 통해 얻는 거의 모든 데이터
- 제안 결과
- 집계 결과
- 매치된 문서 수
- 최대 점수
- 매치된 상위 문서
캐시 활용 방향
- QueryPhase 만 캐싱하는 것, FetchPhase(실제 결과) 캐시가 아니어서 상위 문서가 무엇인지는 캐시하지만 실제 데이터는 다시 패칭해서 가져온다.
적재 위치
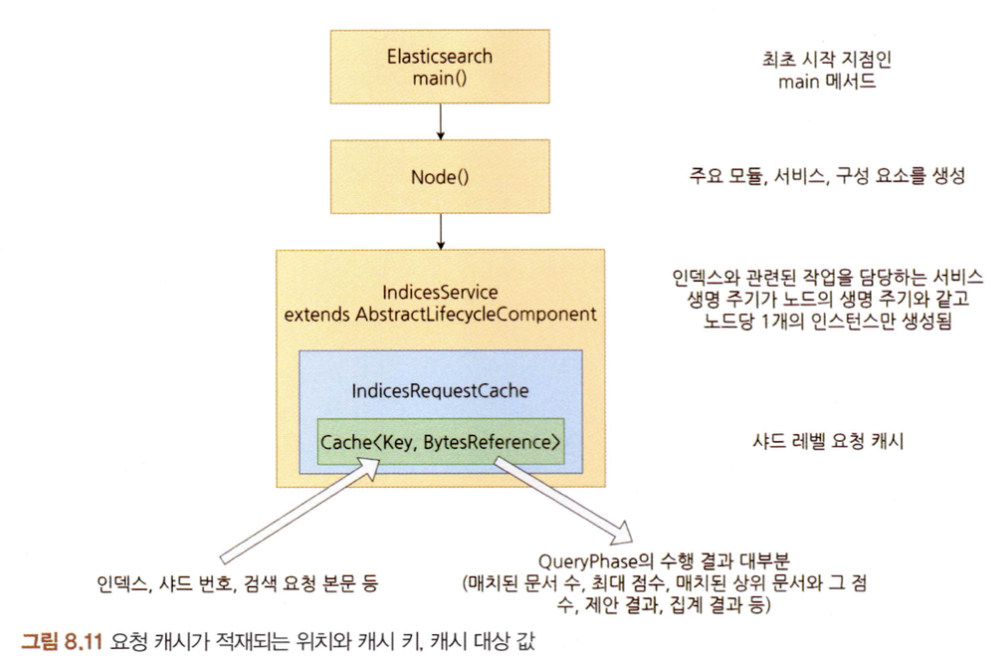
- 엘라스틱서치 노드가 기동하는 과정에서 Node 클래스의 생성자가 호출되며, 여기서 IndicesService 인스턴스가 생성된다.
- 즉 샤드 레벨 요청 캐시 보유하고 있는 곳도 실질적으로 노드와 생명주기가 같은 IndicesService
상태 확인
- *GET _stats/request*cache?human
- 전체 인덱스의 캐시 적중, 부적중, 퇴거(eviction) 회수, 캐시 크기 등의 주요 정보를 확인할 수 있다.
크기 지정과 무효화
- 기본 설정으로는 총 힙의 1%까지 샤드 레벨 요청 캐시로 사용한다
- config/elasticsearch.yml 에 indices.request.cache.size 에 %를 지정하고 노드 재기동하면 이 값을 변경할 수 있다. (예 2%)
- 무효화
- 샤드 레벨 요청 캐시는 인덱스 refersh 수행할 때 무효화된다.
- 수동으로 무효화 → POST [인덱스이름]/_cache/clear?request=true
노드 레벨 쿼리 캐시
- 노드 레벨 쿼리 캐시는 필터 문맥으로 검색 수행 시, 쿼리에 어떤 문서가 매치됐는지를 노드 레벨에 저장하는 캐시다
위치
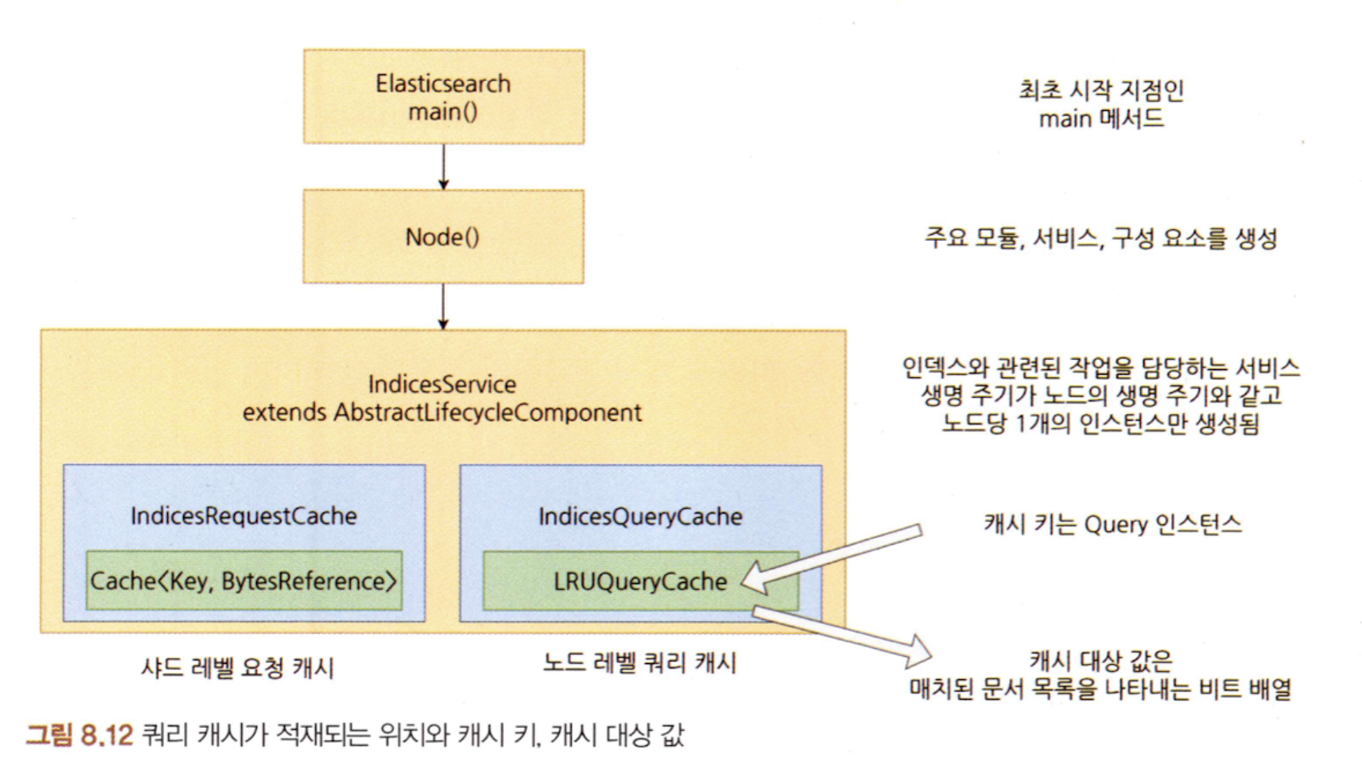
- QueryPhase 검색 수행 시 IndexSearcher의 search 메서드 호출 여기서 createWeight 호출해 weight 생성
대상 값
- DocIdSet 추상클래스, 즉 쿼리에 매치된 문서 목록을 캐시에 적재한다.
- 주로 비트 배열로 구현한다. → 4번 문서가 매치된 경우 배열의 4번 비트를 1로 올린다.
- 문서 수가 검색 대상 문서 수의 1%를 초과하면 밀도 높은 배열로 취급하며, 그때는 DocIdSet 구현체로 FixedbitSet 을 사용한다.
캐시 키
- Query, 즉 Query의 equals와 hashCode 구현상 같은 Query로 취급할 수 있는 쿼리가 들어와야 캐시를 적중시킬 수 있다.
- 캐시 적중률을 높이려면 이 점을 염두에 두어야 한다.
조건
- 유사도 점수를 계산하지 않는 쿼리여야 한다.
- 1만 개 이상의 문서가 있으며, 동시에 샤드 내 문서의 3이상을 보유하고 있는 세그먼트가 대상일 때만 캐시한다.
락 획득
- 노드 레벨 캐시 읽기, 쓰기 작업 모두 락 획득을 필요로 한다.
- 다만 읽기 작업은 최초 락 획득 실패하면 바로 일반 검색 작업 진행
- 일반 작업은 락 획득을 무작정 기다릴 수 없다.
위치
상태 확인
- *GET _*stats/query_cache?human
- 인덱스별 혹은 전체 인덱스의 캐시 적중, 부적중, 퇴가 회수, 캐시 크기 등의 주요 정보 확인 가능
캐시 크기 지정과 캐시 무효화
- 기본으로는 총 힙의 10% 까지 노드 레벨 쿼리 캐시 사용
- 설정 파일의 indices.query.cache.size: 5%
- 무효화
- POST [인덱스 이름]/_cache/clear?query=true
샤드 레벨 요청 캐시와 노드 레벨 쿼리 캐시 비교
운영체제 레벨 페이지 캐시
- 운영체제 레벨에서 기본적으로 동작하는 페이지 캐시가 있다.
- 디스크에서 데이터 읽은 후 데이터를 메모리에 넣어 두었다가 이 데이터 읽을 때 메모리에서 읽어 반환
- ES는 페이지 캐시를 잘 활용함으로 시스템 메몰 절반 이상은 캐시로 사용하도록 설정하는 것이 좋음
'DataOps > Elasticsearch' 카테고리의 다른 글
| [Elasticsearch] 3. 인덱스 설계 (Template, Routing) (0) | 2024.03.13 |
|---|---|
| [Elasticsearch] 3. 인덱스 설계 (Analyzer, Tokenizer) (0) | 2024.03.13 |
| [Elasticsearch] 3. 인덱스 설계 (설정, 맵핑, doc_values, _source) (0) | 2024.03.04 |
| [Elasticsearch] 2. 엘라스틱서치 기본 동작과 구조 (0) | 2024.01.26 |
| [Elasticsearch] 1. 엘라스틱 서치란? (0) | 2024.01.26 |



댓글