메시지 브로커의 필요성
- 여러 모듈이 서로 느슨하고 적절하게 연결시킨 구조를 선호하는데, 이떄 탄탄한 상호작용이 필요해 메시지 브로커를 필요로 한다.
- 서비스 간 커넥션이 실패하는 상황은 언제나 발생할 수 있으며, 되도록 비동기 통신하는 것을 권장한다.
- 메시지를 어딘가에 쌓아 둔 뒤 나중에 처리할 수 있는 채널을 만들어 주는 것, 이것이 메시지 브로커의 핵심 역할이다.
메시지 브로커 타입
1. 메시징 큐

- Producer: 데이터를 생성하는 쪽
- Consumer: 데이터를 수신하는 쪽
2. 이벤트 스트림
- Publisher: 데이터 생성
- Subscriber: 데이터 조회
이벤트 큐 vs 이벤트 스트림
1. 방향성
- 메시지 큐는 생산자가 소비자 큐로 데이터를 직접 푸시. 2곳에서 필요하면 생산자는 2곳으로 각각 데이터를 보내야 함
- 이벤트 스트림은 특정 저장소에 메시지를 보내면 읽고자 하는 소비자들으 스트림에서 메시지를 풀해 갈 수 있어 메세지 복제가 필요 없다.
2. 영속성
- 메시징 큐는 소비자가 데이터를 읽어가면 데이터를 삭제한다.
- 메시징 큐는 새로운 소비자가 추가되면 새로운 메시지부터 확인 가능하다. (카프카의 fromBeginning 옵션)
- 이벤트 스트림은 바로 삭제되지 않고 저장소 설정에 따라 특정 기간 동안 저장될 수 있다.
결론
- 메시징 큐는 일대일 상황에서 다른 서비스에게 동작을 지시할 떄 유용하다.
- 이벤트 스트림은 다대다 상황에서 유리하다.
레디스를 메시지 브로커로 사용하기
pub/sub

- 특정한 채널에 데이터를 전송하면 구독하고 있는 소비자들이 메시지를 소비할 수 있다.
- 한 번 채널 전체에 전파되면 삭제되는 일회성 특징을 가지고 있다. (클러스터 에서는 모든 노드에 메시지를 전달한다)
- 즉 매우 간단하게 사용할 수 있지만 기능은 살짝 부족하다(통로 역할만 한다. 메타 데이터 등도 저장되지 않는다)
- 메시지 잘 전달됐는지 등은 보장하지 않는다.
- fire-and-forget 패턴(간단한 알림) 서비스에서는 유용하게 사용할 수 있다.
fire-and-forget?
- 비동기 프로그래밍 디자인 패턴으로 작업 완료에 대한 처리가 필요하지 않을 떄 사용한다.
- 성공, 실패에 관심이 없는 경우에 활용한다.
- 신뢰성 필요한 경우에는 사용하지 말자.
shareded pub/sub

- 클러스터에서 필요한 채널이 있는 노드 간에만 pub/sub 메시지 전파
- 7.0 부터 개선되었음 spublish
트위터의 레디스 list 메시징 큐로 사용한 예시


- list의 ex 기능을 이용해 pushx 커맨드로 트윗 발생 시, 최근에 타임라인 조회한 팔로워에게 트윗 저장.
- 블로킹 기능이 있어서 (BLPOP) 데이터 들어올 때까지 대기하거나, 타임 아웃 후 nil 을 반환 받을 수 있다.
list 이용한 원형큐

레디스의 Stream
스트림?
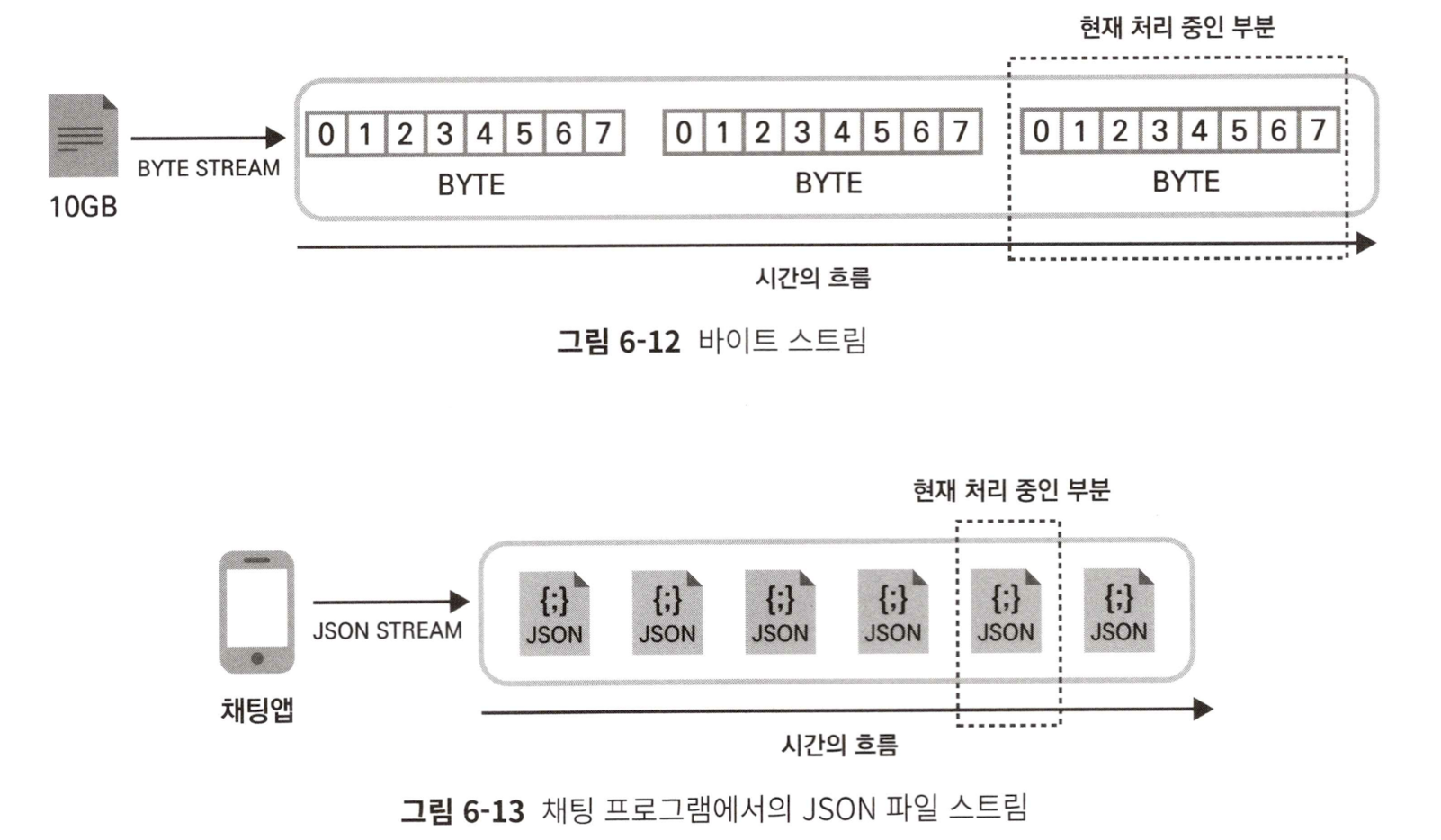
- 컴퓨터 과학에서 스트림이란 연속적인 데이터의 흐름, 일정한 데이터 조각의 연속을 의미한다.
- 일반적으로 Stream 은 업데이트하지 않고, 지우지 않고 쌓기만 한다.
- 끝이 정해지지 않고 계속되는 불규칙한 데이터를 연속으로 반복 처리할 때 이 또한 스트림 처리라고 부른다.

데이터의 저장
메시지의 저장과 식별
카프카
- 토픽이라는 개념으로 분리된 스트림을 의미한다.
- 기본적인 id 패턴: {msTime}-{sequenceNumber} 2개의 파트, 당연 중복x, ms 겹치면 뒤 sn으로 구분, sn은 64bit로 사실 제한이 없는 수준, 사용자가 정해서 넘길 수 있음
레디스
- 레디스는 하나의 Stream 자료 구조가 하나의 stream 의미한다. (XADD)
데이터 조회
카프카
- 소비자가 특정 토픽을 실시간으로 리스닝해서 메시지를 전달 받는다.
레디스
- 읽을 수 있는 방법 2가지 지원, 카프카처럼 실시간 리스닝(XREAD BLOCK 0 STREAMS Email 0, 0부터 실시간 리스닝), ID 이용해 필요한 데이터 검색하는 방법(XRANGE Email - + or XRANGE Email 192939392923 19929349392
소비자와 소비자 그룹
Fan-out
- 같은 데이터를 여러 소비자에게 전달하는 것
카프카

- 컨슈머 그룹의 컨슈머와 파티션이 1:1로 연결된다.
레디스

- 소비자 그룹 내 한 소비자는 다른 소비자 아직 읽지 않은 데이터만 가져간다.
- 즉 하나의 스트림을 병렬로 가져가서 처리하기엔 Redis 가 용이하다.
- 즉 카프카는 파티션이라는 개념으로 소비자 부하 분산 관리하면, Stream 은 파티션 분할 없이도 데이터 분산시킬 수 있다. -> 근데 이래도 브로커 부하분산 되나?
ACK와 보류 리스트

- 재처리 매커니즘을 위해서 어디까지 구독했는지 관리해야 한다.
- 메시지를 읽어가면 읽어간 메시지에 대한 리스트를 새로 생성하고, 읽은 데이터 ID로 last_delivered_id 값을 업데이트 한다. (메시지 중복 전달을 막기 위해)
- ACK 응답을 받기 전에는 보류 리스트에서 메시지를 관리한다.
3가지 전략
At most once
- 메시지를 최소 한 번 보냄.
- 소비자가 처리하기 전에 ACK 보냄.
- 손실될 수 있지만 빠른 응답.
At least once
- 받은 메시지 모두 처리한 뒤 ACK 보냄.
- 한 번 더 처리하는 경우가 생길 수 있음.
Exactly once
- 메시지가 무조건 한 번씩 전송되는 것을 보장.
- set 등의 기타 자료구조를 이용해 발송했는지 확실하게 검증.
'DataOps > Redis' 카테고리의 다른 글
| [Redis] 레디스 데이터 백업 방법 (1) | 2024.06.02 |
|---|---|
| [Redis] 5장. 레디스를 캐시, 세션으로 사용하기 (0) | 2024.05.08 |
| [Redis] 4장. 레디스 자료 구조 활용 사례 (1) | 2024.05.05 |
| [Redis] 3장. 레디스 기본 개념 (0) | 2024.05.05 |
| [Redis] 1장. 마이크로서비스 아키텍처, NoSQL, 레디스 (1) | 2024.04.17 |




댓글